http查漏补缺之一 《缓存》
/ / 点击 / 阅读耗时 14 分钟下面主要关于代理服务器的缓存。
http缓存
使用
Cache-Control控制缓存,不同值之间使用逗号和空格分割。强制确认缓存
Cache-Control: no-cache:每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(注:实际就是返回304),则缓存才使用本地缓存副本。MDN的页面请求头中都带有这个消息头,比如这个页面。
缓存过期机制
Cache-Control: max-age=31536000:max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。比如这个页面的css文件
禁止进行缓存
Cache-Control: no-store缓存验证确认
Cache-Control: must-revalidate如果缓存的响应头信息里含有”Cache-control: must-revalidate”的定义,在浏览的过程中(感觉此处的浏览过程中指的是正常的接到响应)也会触发缓存验证。
Expires
Expires响应头包含日期/时间,即在此时间之后,响应过期。
如果在
Cache-Control相应头设置了 max-age 那么Expires头会被忽略。缓存新鲜度
由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐。
服务器更新一个资源时,不可能直接通知客户端及其缓存,所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是新鲜的,当过了过期时间后,该资源(缓存副本)则变为陈旧的。
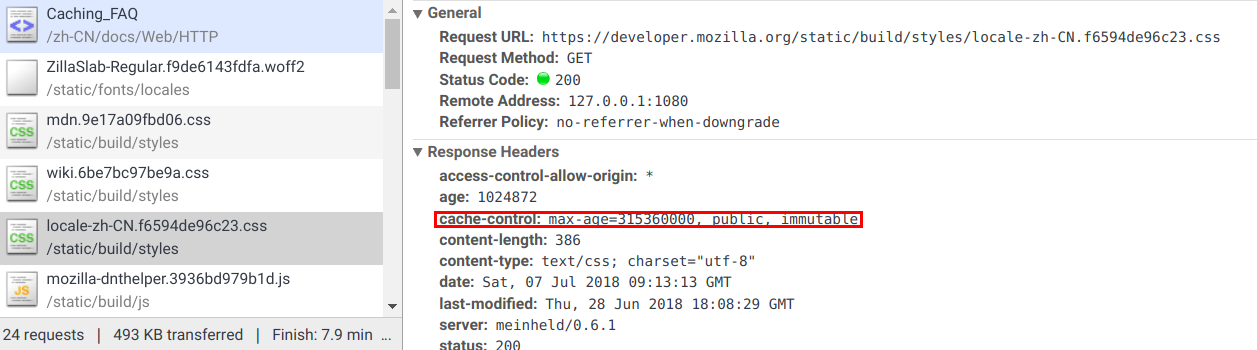
驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个
If-None-Match头,然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,若服务器返回了304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回。见下图描述:
计算缓存寿命
当有比如
Cache-control: max-age=N的请求头这种的特定头,相应的缓存的寿命就是N。如果没有
Cache-control请求头,会去查看是否包含Expires属性,通过比较Expires的值和头里面Date属性的值来判断是否缓存还有效。Expires表示一个日期时间,如果Date表示的日期和时间大于Expires则表示缓存已经过期。如果既没有
Cache-control, 也没有Expires,就会查找头里的Last-Modified信息。如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10。Date表示消息生成的日期和时间。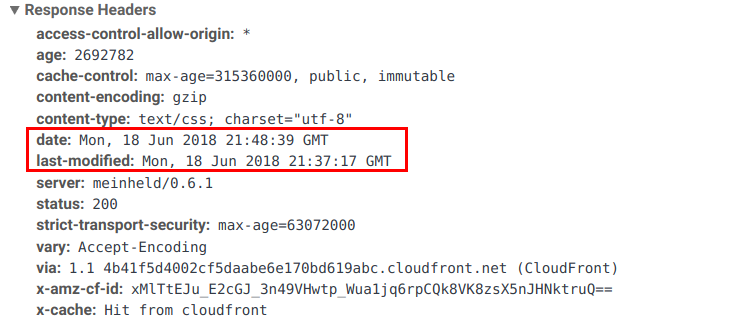
ff和chrome查看缓存的方法
Firefox: Navigate to about:cache.
Chrome: Navigate to chrome://cache.
计算过期时间
MDN上给出的计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
其中,
responseTime:表示浏览器接收到此响应的那个时间点。(感觉这项应该是在浏览器的某处找到)
freshnessLifetime: 表示缓存的寿命。
currentAge: 感觉对应响应头中的age,表示消息对象在缓存代理服务器中存贮的时长
这样 寿命 - 已经存在的时间 + 最近一次到达浏览器的时间 就得到未来缓存过期的时间。
资源加速
下面这个要问一下。
更多地利用缓存资源,可以提高网站的性能和相应速度。为了优化缓存,过期时间设置得尽量长是一种很好的策略。对于定期或者频繁更新的资源,这么做是比较稳妥的,但是对于那些长期不更新的资源会有点问题。这些固定的资源在一定时间内受益于这种长期保持的缓存策略,但一旦要更新就会很困难。特指网页上引入的一些js/css文件,当它们变动时需要尽快更新线上资源。
web开发者发明了一种 Steve Sounders 称作加速(译者注:revving)的技术[1] 。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
这种方法还有一个好处:同时更新两个缓存资源不会造成部分缓存先更新而引起新旧文件内容不一致。对于互相有依赖关系的css和js文件,避免这种不一致性是非常重要的。
加在加速文件后面的版本号不一定是一个正式的版本号字符串,如1.1.3这样或者其他固定自增的版本数。它可以是任何防止缓存碰撞的标记例如hash或者时间戳。
缓存验证
缓存验证出发的方法:
用户点击刷新按钮时会开始缓存验证;
如果缓存的响应头信息里含有”Cache-control: must-revalidate”的定义,在浏览的过程中也会触发缓存验证。(已在上面做了解释)
在浏览器偏好设置里设置Advanced->Cache为强制验证缓存也能达到相同的效果。
只要出发了缓存验证在请求中就会带有条件
If-None-Match或If-Modified-Since(?),不带条件的请求就会重新获取资源。
缓存过期后的处理方法
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。
缓存校验
触发条件: 只有在服务器返回强校验器或者弱校验器时才会进行验证。
如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
结果:当向服务端发起缓存校验的请求时,服务端会返回 200 ok表示返回正常的结果或者 304 Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间。
带Vary头的响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。

使用vary头有利于内容服务的动态多样性。
例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。(但这样的话岂不是要写移动和桌面端两份文件,对于前端就是包袱啊!!!不如媒体查询来的方便!!!)